Las organizaciones científicas de los sectores público y privado deben adoptar estrategias de manejo de datos que los mantengan acordes con el surgimiento de los grandes volúmenes de datos, si esperan realizar investigación de manera eficaz y precisa. El CIMMYT y muchas otras organizaciones científicas que dependen de donadores operan en ámbitos donde los recursos económicos son cada vez menos y tienen que hacer rendir los recursos de que disponen. Las estrategias de manejo de datos basadas en el concepto data lake (lago de datos) son esenciales para hacer mejores análisis y crear mayores impactos.
Nosotros generamos 2.5 quintillones de bytes diariamente –una cantidad tan grande que el 90% de los datos en el mundo de hoy se han creado en tan solo los dos últimos años. Estos datos provienen de todos lados: de los sensores que recopilan información climática, de los drones que capturan imágenes de los ensayos de mejoramiento, lo que se publica en las redes sociales, las señales de los GPS de los teléfonos móviles, junto con las fuentes de datos tradicionales como las encuestas y los registros de los ensayos en campo. Estos datos son macrodatos o datos masivos, es decir, datos caracterizados por volumen, velocidad y variedad.
Las estrategias de manejo de datos del siglo 20 se enfocaban en asegurar que los datos estuvieran disponibles en bases de datos y/o en almacenes de datos, en formatos y estructuras normalizados –una combinación de numerosas y diferentes bases de datos para toda la empresa. El mayor inconveniente del concepto almacén de datos es que se considera que es demasiado problemático poner los datos en el sistema y que los beneficios directos son pocos, y esto desmotiva que haya repositorios de datos a nivel corporativo. El resultado es que dentro de muchas organizaciones, incluido el CIMMYT, no todos los datos son accesibles.
La tecnología y las herramientas de procesamiento de hoy, como la computación en la nube y el software de fuente abierta (como R y Hadoop), nos han permitido aprovechar los macrodatos para responder preguntas que no podíamos contestar en el pasado. Sin embargo, junto con esta oportunidad tenemos el reto de crear opciones en vez de sistemas de bases de datos tradicionales, ya que los macrodatos son demasiado grandes, demasiado rápidos, o no se adaptan a las antiguas estructuras.
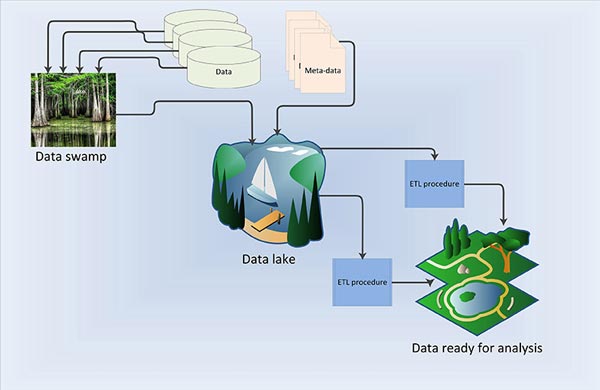
Un sistema opcional de almacenaje y recuperación que puede manejar macrodatos es el lago de datos. Los lagos de datos son sistemas de almacenamiento de todo tipo de macrodatos; son un repositorio de fácil acceso y centralizado de grandes volúmenes de datos estructurados y no estructurados.
Los defensores del concepto creen que es posible capturar y almacenar en un lago de datos todos y cada uno de los datos que se generan. Esto permite hacer más preguntas y dar mejores respuestas gracias a las nuevas tecnologías de TI y garantiza flexibilidad y agilidad.
Sin embargo, sin metadatos –la información que describe los datos que estamos recolectando–– y un mecanismo para conservarlos, los lagos de datos se pueden convertir en pantanos donde los datos son tenebrosos, innavegables, tienen orígenes desconocidos y, al final, no son confiables. Esto significa que cada vez que los científicos y los investigadores quieran usar los datos tendrán que empezar de cero. Los metadatos permiten también la creación e implementación de procesos para extraer, transformar y cargar (ETL) datos, y procesarlos para realizar más análisis.
Los metadatos y los procedimientos ETL bien definidos son esenciales para que los lagos de datos tengan éxito. Muchos de los datos del CIMMYT se encuentran en un pantano debido a la falta de estas dos estructuras esenciales. Los datos genómicos son una excepción, ya que requieren un manejo intensivo por la gran cantidad de datos que el CIMMYT recopila. Además, los datos de la secuenciación de genes están bien estructurados y es más fácil administrarlos en comparación con otros datos, como los de ensayos en campo y de encuestas.
Rara vez, cuando la estructura y el contenido de los datos son obvios, el hecho de que los datos se encuentren aún en el pantano no constituye un problema serio porque podemos definir su estructura fácilmente, creando un schema-on-read en cuanto se define el uso que se dará a los datos. A diferencia de ETL, los datos se estructuran según un plan o esquema cuando se extraen de un sitio de almacenamiento en lugar de hacerlo cuando son almacenados. La desventaja de crear un sistema schema-on-read es que suele requerir mucho tiempo y ser difícil, si se hace por separado de la entrada de los datos, y requiere que uno defina por separado tanto los metadatos como los procedimientos de ETL para asegurar que se puedan usar en diversos análisis. A pesar del apoyo que dan a schema-on-read los defensores de los lagos de datos, el esfuerzo y la información que se requieren para crearlo con frecuencia hacen que el proceso resulte inútil.
Por tanto, es esencial crear una estrategia de lago de datos con metadatos y procedimientos ETL como base para que el CIMMYT maximice el uso y reutilización de datos y para realizar análisis precisos e impactantes. Los siguientes pasos incluyen educar a los científicos y los administradores, y crear procedimientos que respalden la implementación de un lago de datos. Lo ideal sería que esto diera lugar a una base de datos de metadatos con una interfaz de fácil uso que permita estudiar los metadatos de los datos y los procedimientos ETL relacionados, haciendo que el uso, la reutilización y la integración de los datos sea más fácil y rápida y que la investigación para el desarrollo sea más eficaz y eficiente.